Abstract
A SAP ERP system cannot retain the entire history with all individual changes. The amount of data is simply too much. But if there would be a technical solution, the possibilities are limitless.
By continuously pushing change data from S/4Hana to Apache Kafka the ERP system is the realtime business backbone and Kafka the realtime change log.
Use Cases
All changes from the ERP system are streamed into the target.
All changes of remote systems are streamed into the ERP system.
All changes since the last delta are and loaded into SAP BW.
All data comes in two flavors, the original data and a version with cleansed data. Consumers can pick either.
As the cleansing result is attached to the data, reporting on the data is easy. “Find all records that violated Rule #2”
A consumer of the cleansed data can trigger alerts to notify users immediately of severe issues.
In today’s world the ERP system provides data to multiple connected applications. If the ERP system has to provide the data just once and all downstream systems pick it up from there, the ERP system is freed up from sending the same changes to multiple systems.
Storyline
Every change in the ERP system is posted to Apache Kafka immediately. From there Consumers can either listen on the changes for sub second latency, for realtime processing or to read the changes at their convenience.
Apache Kafka is similar to a database transaction log but scaled for Big Data scenarios. So exactly what is needed to enable storing the massive amounts of intermediate changes.
Great care has been taken to ensure the consistency of the data is retained even in Kafka.
Services can now listen on the changed data and bring this data to a higher quality. Examples of such services are
- Validation service: Rules are applied on each incoming record and the information if the record is good, bad or of type warning is attached to the record. Also adds which rules were tested and their individual result.
- Cleansing service: Takes the incoming data and does cleanse the records, e.g. standardize on a single spelling for Male, female, f, unknown, ?, x,…
- Enrichment service: Derive from the incoming data new information, e.g. from the country code the sales region.
- Profiling service: While the data streams in, update the current statistics to see patterns in the data, like more and more incomplete data is sent by a specific source system.
- Alerting service: If a certain conditions apply, e.g. a mandatory field from a source is not present, send an email to somebody proactively.
- ML service for customer categorization.
- …
How it works
A Producer is a web application connected to a source system and sending changes to Apache Kafka. The producers identifies the changes in the source system, assembles the business object and sends the changes.
Consumers read the data from Apache Kafka and write it into the target system. Consumers are in full control of what they want to read. They can read the data since the last read (batch delta), they can listen to changes (realtime streaming), they can read the transaction log from any point in time.
Services are implemented as Kafka KStreams and perform inflight operations on the data. A Rules service for example would listen to new data, run the various tests, adds the test results to the record and puts the data into Kafka again.
Is the backend to choreograph the data between producer, consumer and services. The data is organized in topics – these are the change data queues – and schemas, the business objects. Within a topic the data is processed strictly in order, so for a perfect transactional guarantee all data has to go through a single topic at the costs of less parallel processing.
Architecture
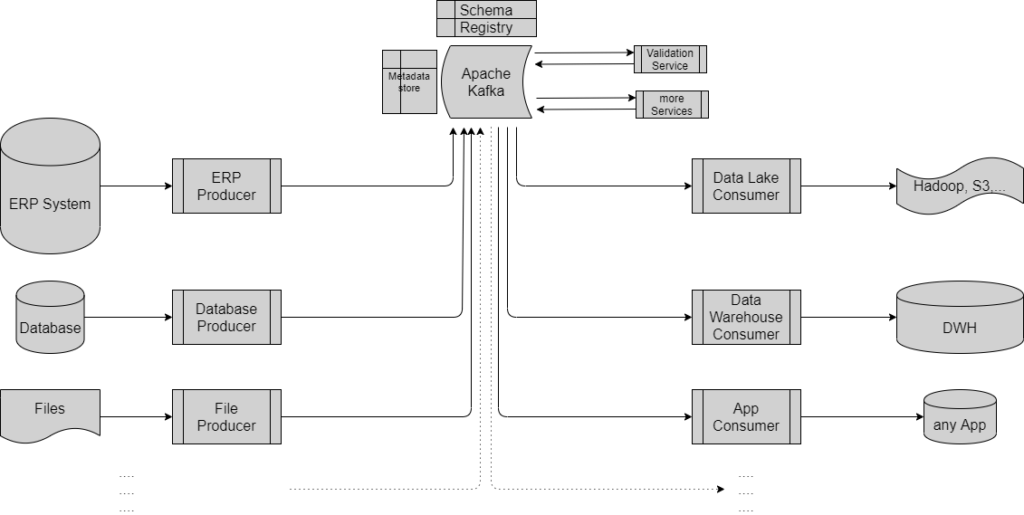
The heart and sole of the solution is Apache Kafka. It is the backend allowing to produce data, consume data and to attach microservices to process the data.
One part of Kafka is the schema registry, a store where the logical data model of all data structures is maintained. But this data model is not as rigid as with databases, it is more Big Data orientated supporting schema evolution, extension concepts, backward and forward compatibility etc. Another part is a Metadata store to keep track of the lineage of services and the current landscape.
Although producers and consumers can interact with Kafka directly via the native TCP protocol, in most cases the data should be streamed via https, hence no holes have to be pocked into the corporate network firewalls.
Kafka also supports streaming transformations to implement various services. The consumers are – required permissions assumed – free to choose whatever data they want to consume and when.
Data Model
Kafka itself can deal with any kind of payload. This flexibility is nice but data integration without even knowing the structure is, well, difficult.
Therefore Kafka is backed by a schema registry where all known schemas are available, including additional metadata, and producers have the task to produce the data according to the structure and the rules of the schemas. Having said that, producers can create or extend schemas automatically.
On the root level, each schema has additional fields about record origin, time of change, type of change.
On the root level is a structure to store transformation results. Every producer and service can add information. As a result the consumer knows what transformations a record did undergo. For example a FileProducer can explain that one line ended premature and categorize that fact as a warning. A validation service can complain that a field was not set although it should have been.
Every record level has an Extension array. This is an opportunity to store any data as key-value pairs without the need to modify the data model at all.
For example the logical data model defines a field GENDER as a string but the source system has a number instead where “1” stands for “female”. Could be interesting to add the original number for auditing reasons. Hence the producer adds the key-value pair “Gender original value” = 1 into the Extension array.
Although a relational schema is possible, as one producer is generating the data for many consumers and services, the suggestion is to go more towards sending business objects.
In the left side example the data is stored in two tables in the source, the order header and the line items table. But instead of sending change information on each of the two tables, produce the entire sales order, with the line items being a sub-array of the order. Yes, that requires a join but better join once than every consumer has to perform the join individually.