

Usually the IT systems are grown. A site built something on their own and in their local data center and common data is rolled up to the region and HQ.
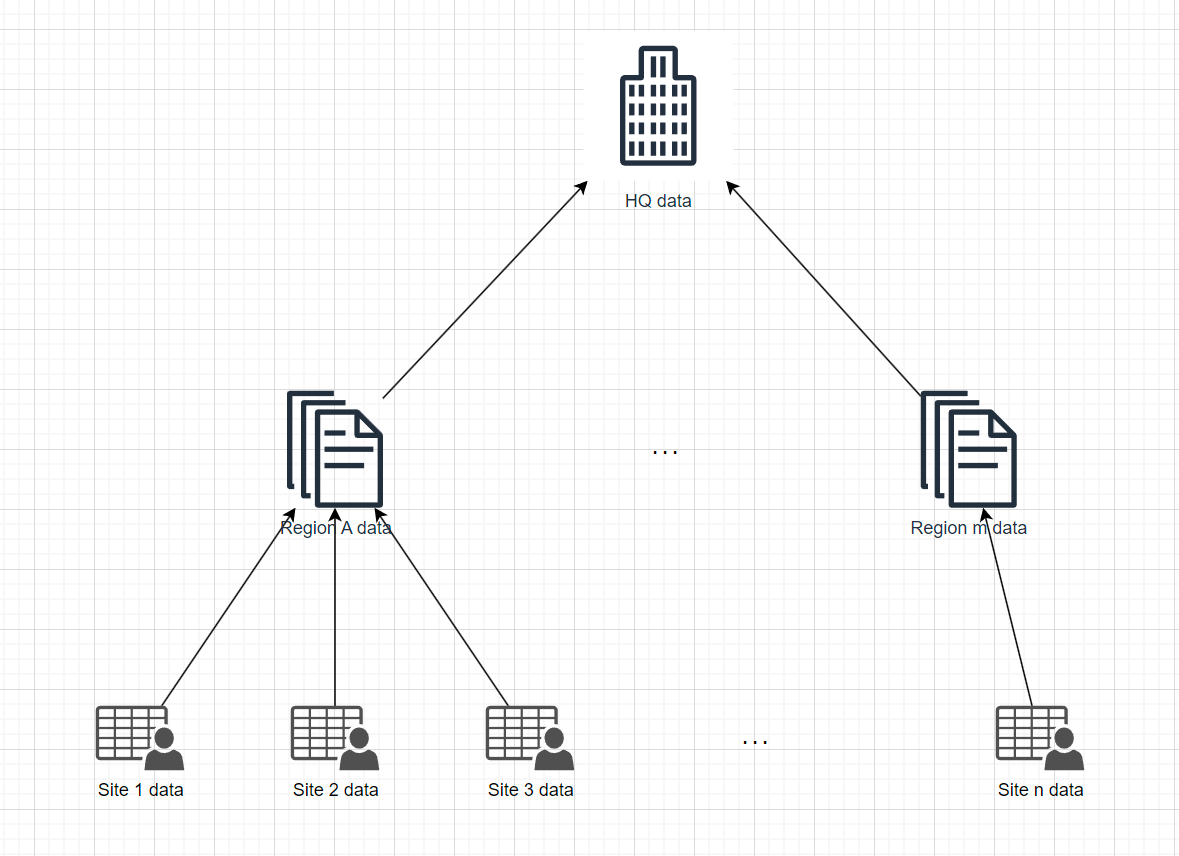
The logical consequence is, with each roll up, information is lost. The site has all the details, the regional organization data from multiple sites but with less detail and HW only the summary.
The deployment reflects that as well: Each location has its own database with data it had requested. That can certainly be improved.
The DG Part 1 proposed an extensible data model as solution. This allows to harmonize shared data and yet gives the option to add additional data unique to the site.
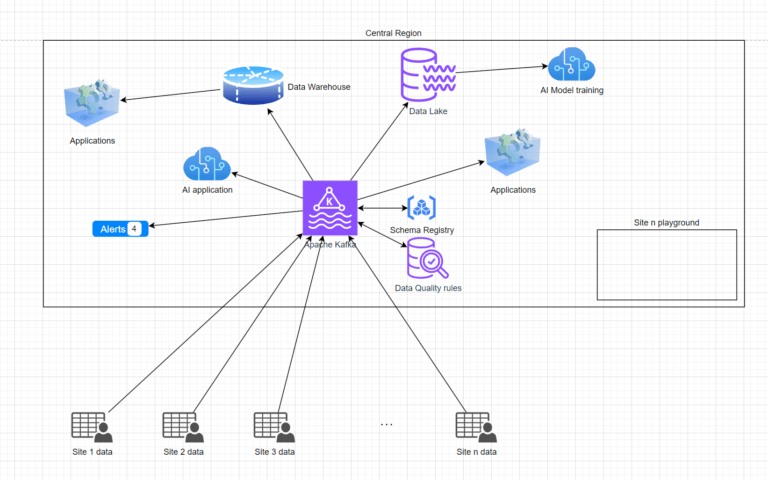
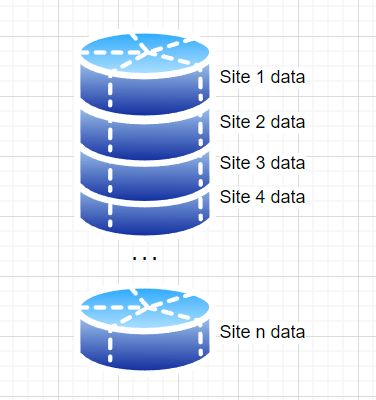
Hence the idea should be that each site is just a partition of all data. Regional data is a view spanning a few partitions, HQ is a view of all partitions.
With all data in close proximity, within the same database even, processing one site, multiple sites or all data is very fast. Each site would still have a database schema of its own in this central database to grant the sites a high degree of freedom. The site has access to its data only but can do whatever it likes. For Data Lake storage it is the same partitioned approach with each site owning a directory with their data.
Create new applications, test drive services, run programs, report on all their data.
Further advantages are:
The main downside is the increased latency for users from the other side of the planet. But replicating data 1:1 to other cloud regions is a normal operation and can be done easily, if needed. Combining data from different regions and harmonizing is the difficult bit and the reason for long running integration projects.
Managing the permissions and proper naming conventions are the important building blocks for a successful project. How this is done depends on the services used and the Cloud vendor. Each site has their own accounts with full flexibility and the data is granted via cross account permissions (AWS speak)?