A Business Rules Service for Kafka
Container & readme: dockerhub
The requirements for enterprise grade data quality solutions are:
- A Web UI for business users to maintain the rules: The business users know the data, not IT!
- Keeping track on what rules have been executed for each row and their result: Rule might have been added, rules might not have been executed because the previous rule failed already.
- The aggregated information if the row is valid, violated rules or has a warning: If one rule returned a fail-indicator and another a warning, the entire row is of state failed.
- Data Quality dashboards to analyze what rules have been violated and the trends: In the previous years just a few records were faulty, recently more and more are coming in – what has changed?
- Analyzing the rule violations per every record attribute: Was the rule violated in one region or across all regions?; Did it affect one product or across all products?
- Git integration for multi user and CI/CD enablement.
It is achieved is by adding a Web UI deeply integrated with Kafka to maintain rules comfortably and with sample data.
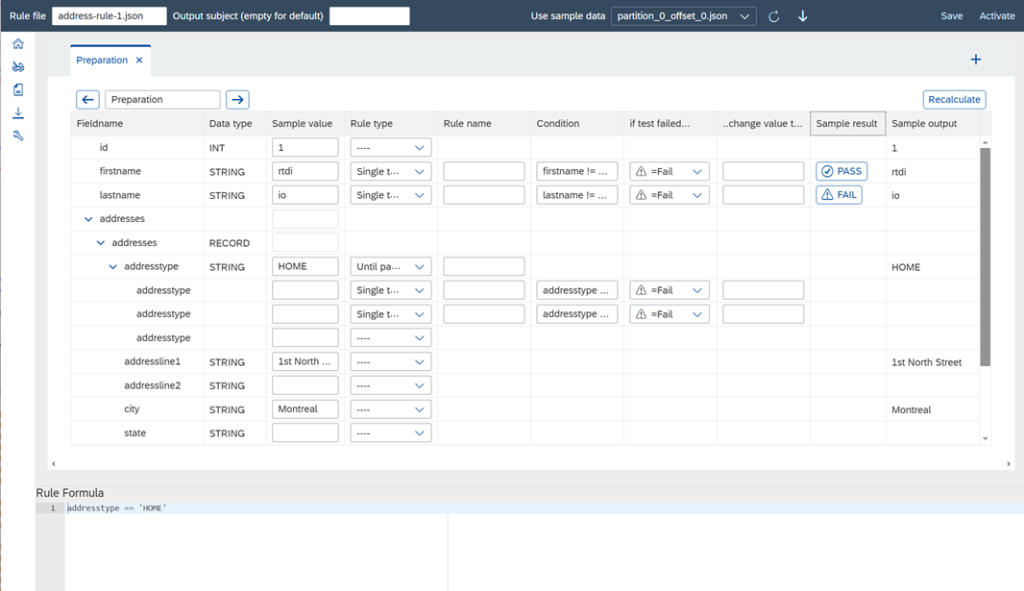
Once the rules are configured and deployed, they get assigned to an input Kafka topic and are executed one every incoming record.
The rule results are attached to each record inside an additional field of that record and written into an output topic. Thus consumers have the option to either read the raw data or the cleansed data, they can use the audit information and if the audit information is persisted in the Lakehouse, BI tools are used to visualize the rule results.
This allows to build applications like
- Synchronize two operational systems but only for records that are valid.
- Show the data quality metric in the BI tools when querying the data, e.g. watch out, 1% of the records have an invalid country code.
- Enrich the data, e.g. if the order number starts with a ’10’, then set the order type to “online sales”.
- Standardize the data to make sure a field only contains the allowed values or a ‘?’, never null values, to help the user analyzing the data.